Overview
In discussing Slowly Changing Dimension, the first thing you must consider is first of all, your attributes type. Base on this, you will have various SCD types or combination of types.
Dimension Attribute Types:
- Type 0: dimension attribute that never changes.
- Type 1: dimension attribute that is overwritten with new values/changes
- Type 2: dimension attribute on which we track changes of a value ( for same logical tuple in the table, you will have multiple records representing the changes occurring on that column).
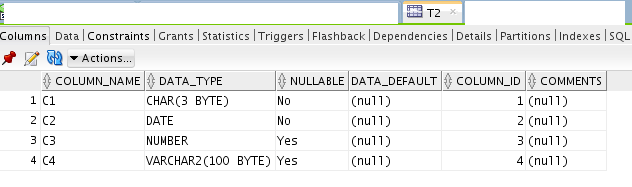
To discuss the various types of columns, let’s take a more generic table example.
We have table DEMO_SCD created for this purpose, with following structure: And have inserted a couple of test records/tuples for this:
And have inserted a couple of test records/tuples for this: In the following definitions, I will define a logical tuple as information identified in a record or records by the natural key.
In the following definitions, I will define a logical tuple as information identified in a record or records by the natural key.
Dimension attributes types
Type 0 – never changing
These will represent the columns that stay in their original state all the time. This does not imply though that new values of this column cannot be introduced into the dimension. It implies only that for a logical tuple, the information will never change in time, independently of the other columns information for the given table.
One example for this type is the audit creation columns (created by, created date), which will not be changes when the information in the main table changes.
Another example is the natural key of the table (in our test table the ROW_CODE).
The overall constraint on this type is the fact that the information once inserted, it will not change in time.
Type 1 – Volatile Value
These will represent the columns that will change in time, losing the original state. Information can be added, deleted or modified at will. This implies that for a logical tuple, the information will always contain the current/most recent data.
An example of this type of columns represents the audit update columns (last update date, last updated by), whose scope is to capture the last person manipulating a tuple.
Type 2 – Versioning Values
These are columns on which the evolution in time of the value is of interest to the analyst. This implies that values for this column can be inserted, but never updated or deleted. However, this also implies that additional columns are required to implement this, in order to keep track of versioning history, and be able to identify the current data.
I am going to cover only 2 of the implementation options possible:
- Versioning
- Time based / Active time range /effective dates
Versioning
Versioning containing tables will look like the following example:
Please note the tuple of AA, where the change in status generated a second record with an increased version number.

Please note here the VERSION column, which keeps track of the changing of data.
On joining with a versioned SCD, a fact table would have to join by
- Surrogate key – ROW_ID – this way the identification of correct version is done on populating the fact, and not at reporting time)
- Natural key and version number
- Natural key and maximum version (if we report only on current data)
- Natural key and 0 version (if we report on original data)
Effective Dates
Implementation using effective dates would imply the existence of 1 or 2 date columns which would identify the period the record is active for.
Since the implementation containing one date column would make the identification of a specific information/version of a tuple at a given point in time more difficult, I would always suggest the implementation containing two date columns.

Same change on tuple AA is now represented in this example

Please note here the START_DATE and END_DATE columns, which keep track of the changing of data.
On joining with a time based SCD, a fact table would have to join by
- Surrogate key – ROW_ID – this way the identification of correct version is done on populating the fact, and not at reporting time)
- Natural key and join on start_Date, end_date columns
- Natural key and current version(identified by end_date null) (if we report only on current data)
Please note that both type 2 columns implementation involve:
- Updating current record for working tuple
- Inserting new record with different surrogate key for working tuple
Dimension types
Now, based on the analysis of the column types, we can identify multiple versions of SCD
- Type 0 – only Type 0 columns;
- Type 1 – contains type 0 and 1 columns;
- Type 2 – contains type 2 columns;
- Type 3 – contains type 2 columns;
- Type 4 – contains type 2 columns;
- Type 6 – contains type 2 columns;
Type 0 – Static Tables
This type of table is, from what I see, rarely found in a Data warehouse, but the most frequent example would be a log table. This type of dimension would have data that only gents inserted, and never gets modified.
Type 1 – Current Data Tables
These are the tables where we’re only recording the current version of events. Every single update will modify the exiting tuple in the table, and no historical reporting is possible on this scenario.
Type 2
This type tracks history by creating multiple entries for a given tuple. Unlimited history is preserved for each.
Implementation examples for this are the ones presented for the Type 2 columns.
Type 3
This method will only keep a limited history for each tuple.
The implementation implies additional columns that will keep the last value of a given attribute that we are tracking, or the original state of that column.
This is however very limited, as multiple changes on the same tuple will not be tracked.
Example for this type:

Please note the ORIGINAL_DESCRIPTION column capturing the original information for the description of the tuple at the time this was created.

Please note in this example the PRIOR_STATUS. In this implementation, we will only track the last change; the original value will no longer be available for reporting.
Type 4
This is a slightly different scenario, involving 2 tables to keep the tuple information:
- Current table – only current information
- History table – part of or all historical information
Both tables will have to be used in reporting, by joining with the fact with each table’s surrogate key.
Example of current table implementation:

and associated history table:

Note the AA tuple within the 2 tables.
Type 6
The Type 6 method combines the approaches of types 1, 2 and 3 (1 + 2 + 3 = 6). Ralph Kimball calls this method “Unpredictable Changes with Single-Version Overlay” in The Data Warehouse Toolkit.

Please note data modifications for tuple identified by ROW_CODE = ‘AA’
You will notice that for current record (current flag is ‘Y’), the current status and historical status as always the same.
Note also that the tuple can pass multiple times through the same status.
General classification source: Wikipedia