Indexing is one of the most frequent approaches when resolving query performance issues raised within a database (though not necessary the right approach, but we can pick this up later).
However, in order to better use indexing strategies, we should go trough the process on understanding index types and their functionality.
First of all, please keep in mind that an index is logically and physically independent of the data they represent. This implies that modifying the index will not affect the data consistency within the table the index is associated with.
It can be created on one or more columns of a table to enable queries to retrieve a small set of randomly distributed rows while reducing the cost of that operation, by reducing the IO associated with the alternative full table scan.
The general considerations for creating an index would be
- Unique indexes for candidate unique/pk columns, to enable naming the index when creating the associate constraint on the table;
- a referential constraint column
- columns used in frequent queries with high selectivity (columns on which the filters applied would enable the return of a small percentage of the rows in the table).
! Note: Primary and unique keys automatically have indexes, but you might want to create an index on a foreign key.
Indexes are automatically maintained by the database with no additional action required by the user. This however, does not imply that an index comes without costs. Always, indexes will improve query performance, but decrease performance on data manipulations. That is due to the fact that any insert/update/delete will have to maintain both objects: the table the DML is submitted on as well as the index update.
When testing an indexing strategy, a developer can take advantage of the following properties of the indexes:
- usability
- visibility
Usability: Indexes are by default usable. An unusable index will both not be maintained by the DML operations, nor will it be used by the optimizer. This property can help improve performance on bulk loads. Instead of dropping and recreating the index, we can easily make it unusable and then rebuild.
! Note: Unusable indexes and index partitions do not consume space. When you make a usable index unusable, the database drops its index segment.
Syntax:
to set an index to unused:
alter index test_idx unusable;

to rebuild index:
alter index test_idx rebuild;

Visibility: Indexes are by default visible. An invisible index will still be maintained by DML operations but will not be used by the optimizer. Invisible indexes are especially useful for testing the removal of an index before dropping it or using indexes temporarily without affecting the overall application.
alter index test_idx invisible;

alter index test_idx visible;
to restore the index.
Index types (based on column number):
- single key index
- composite index
Index types (based on data content):
- unique
- nonunique
Nonunique indexes permit duplicates values in the indexed column or columns. For a nonunique index, the rowid is included in the key in sorted order, so nonunique indexes are sorted by the index key and rowid (ascending).
!Note: Oracle Database does not index table rows in which all key columns are null, except for bitmap indexes or when the cluster key column value is null.
Index types (based on structure of the index):
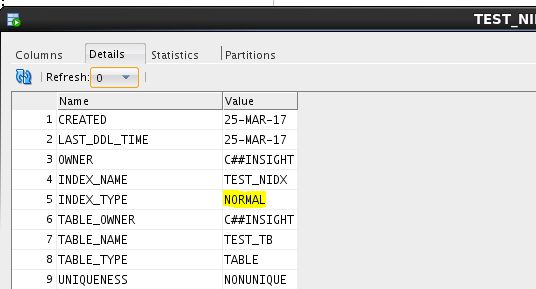
- B-tree (balanced tree index) (standard type)
- Index Organized Table (IOT)
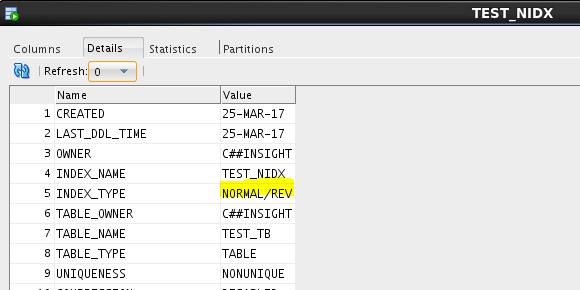
- Reverse key index
- Descending index
- B-tree cluster index
- bitmap and bitmap join index
- function based index
B-tree:
- excellent for PK and highly-selective indexing
- data retrieved sorted by the indexed columns
By associating a key with a row or range of rows, B-trees provide excellent retrieval performance for a wide range of queries, including exact match and range searches.
IOT – this table differs from classical (heap-organized) table by the fact the data is in the index itself.
For more details on IOTs, please see related article here.
B-tree cluster indexes – is used to index a table cluster key. Instead of pointing to a row, the key points to the block that contains rows related to the cluster key.
In a bitmap index, an index entry uses a bitmap to point to multiple rows. In contrast, a B-tree index entry points to a single row. A bitmap join index is a bitmap index for the join of two or more tables.
More on bitmap indexes here.
Function based index: This type of index includes columns that are either transformed by a function, such as the UPPER function, or included in an expression. B-tree or bitmap indexes can be function-based. Example of function base b-tree here.