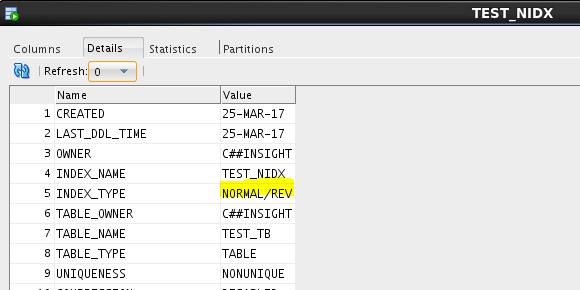
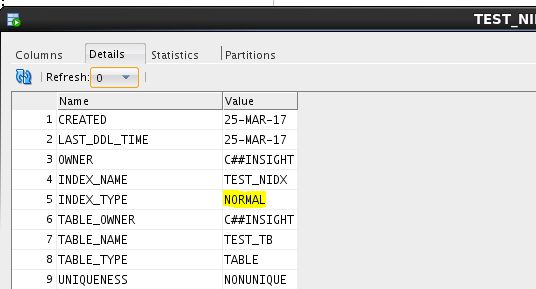
We discussed earlier about indexing, and specifically reverse key indexing.
I mentioned that is a solution for buffer busy waits on numerical consecutive inserted keys (like the sequence based generated ones) .
This post will test that solution.
For regular index test, I’ve created the following table, sequence and associated index:
create table test_tb ( row_id number , text varchar2(100)); create sequence test_seq start with 1 increment by 1 cache 10000; create index test_nidx on test_tb(row_id);
and a simple procedure that will insert the rows:
create or replace procedure insert_n (p_rows number default 10000) as begin for i in 1..p_rows loop insert into test_tb select test_seq.nextval, 'test row '||test_seq.currval from dual; end loop; commit; end; /
For the reverse key index test:
create table test_tb2 ( row_id number , text varchar2(100)); create sequence test_seq2 start with 1 increment by 1 cache 10000; create index test_ridx on test_tb2(row_id);
and a simple procedure that will insert the rows:
create or replace procedure insert_r (p_rows number default 10000) as begin for i in 1..p_rows loop insert into test_tb2 select test_seq2.nextval, 'test row '||test_seq2.currval from dual; end loop; commit; end; /
To test the effect of concurrent inserts, I’ve executed both procedures from 3 sessions (please note in my case number of sessions is small, but will still show us the impact of the two types of indexes):
execute insert_n(100000); execute insert_n(100000);
Now looking at the buffer busy waits we had we see a reasonable benefit already of the reverse key index:


select object_name, value, statistic_name,object_type from v$segment_statistics where owner='C##INSIGHT' and object_type='INDEX' and statistic_name='buffer busy waits' and object_name like 'TEST%' ;