
The following post will walk you trough an exercise of creating a partitioned table, using the range partitioning (with auto define of partition names), populating and testing the partition pruning.
Please note I will also post the scripts at each section so you can replicate the work.
Creating our Work Table:
I’m creating a sample table T2 with 4 columns, with the following structure:
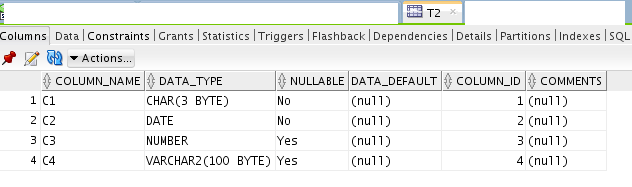
SQL:
create table t2 (c1 char(3) not null , c2 date not null , c3 number , c4 varchar2(100)) partition by range(c2) interval (numtodsinterval (1,'day')) ( partition empty values less than (to_Date ('03-OCT-2016', 'dd-mon-yyyy')) ) ;
We want to partition this table by the C2 column, which is a date column: not null, splitting the data into a non-prior-defined number of categories.
I’m generating a sample data set of about 100 000 rows.

And afterwards, please note a very important step, I’m gathering my stats 🙂
insert into t2 select case when mod(level,20) <11 then 'ABC' when mod(level,20) >10 then 'ACD' end as c1 , sysdate+level/24/60 , level , 'test record '||level from dual connect by level <=100000; commit; execute dbms_stats.gather_table_stats(user,'T2');
Partition Pruning:
Now, let’s run a couple of test to see how partition is actually helping our performance.
Please note that i used “Autotrace” to show the actual plan and the partition pruning for our selects.
First scenario:
select * from t2;
This is our base test: select all data from our partitioned table:

Second scenario:
select * from t2 where c1='ABC';
Selecting data filtering on a non-partition key.

Third scenario:
select * from t2 where c1 = (select /*+ no_unnest + result_cache*/ (to_Date ('05-OCT-2016', 'dd-mon-yyyy')) from dual) ;
Filtering on one of the values of the partition key, ’05-OCT-2016′:

Third scenario:
select * from t2 where c1 < (select /*+ no_unnest + result_cache*/ (to_Date ('07-OCT-2016', 'dd-mon-yyyy')) from dual) ;
Filtering on multiple values of our partition key :

Conclusions:
I’ve been using the SQLDeveloper Autotrace to demonstrate the partition pruning.
As you can see, the selects will do partition pruning when filtering on one or multiple partitions.
Also, please note the initially defined partitions are names as expected, while the rest of the data, on insert, generated automatically new partitions, named by the system.

One thought on “Oracle: Partition by Range– Example”